Your AI infrastructure should be an advantage.
Not a vendor management problem.
With STN GPU One, you get one partner accountable for every layer. No gaps. No handoffs. No moment where your AI program is someone else's problem. HPE-engineered. NVIDIA-validated. One operator across the full stack.

STN GPU One — One Operator.
Every Layer.
GB300 NVL72. Reserved, not rented.
OEM-aligned allocation through HPE — not spot sourced, not brokered. 99.999% uptime SLA . 24/7 NOC.
We own what we promise.
265 MW of operational power, scaling to 725 MW across three owned sites. One contract. No intermediaries.
The stack the world's most demanding AI runs on.
HPE engineered the platform. NVIDIA validated the stack — Mission Control, Dynamo, AI Enterprise, TensorRT-LLM. Purpose-built, not retrofitted.
Start at 32 nodes. Scale to 10,000+ GPUs.
Same environment. Same network. Same team. No replatforming event. No ceiling you have to negotiate your way past.
The GPU One Infrastructure Stack
Purpose-built architecture for high-performance AI and GPU workloads.
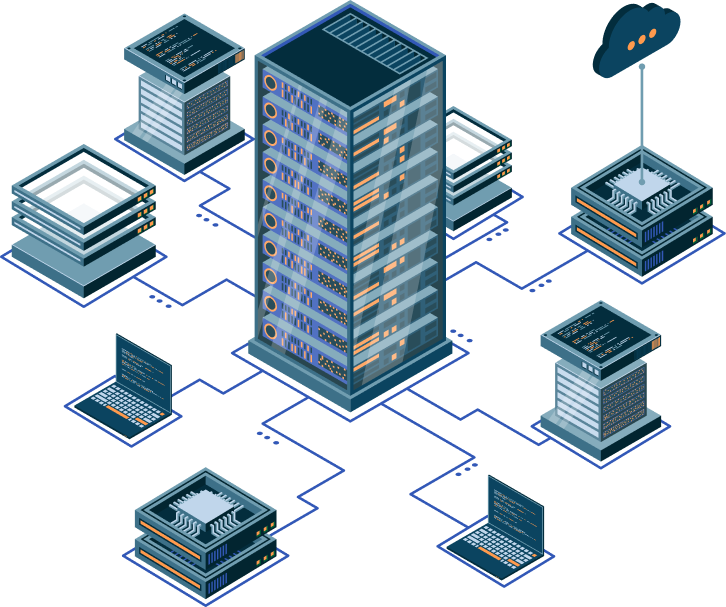
High-Performance Compute
- GPU Compute Instances
- CPU Compute Nodes
- High-Speed Local NVMe Storage
High-Throughput Storage
- Parallel AI Data Storage
- High-Bandwidth Dataset Access
- Scalable Petabyte Capacity
High-Performance Networking
- Low-Latency Cluster Fabric
- Multi-Node GPU Communication
- Secure Tenant Isolation
Container & Orchestration Platform
- Managed Kubernetes
- GPU-Aware Scheduling
- Automated Cluster Provisioning
Platform Services
- Infrastructure Automation
- API & Developer Access
- Backup & Data Services
Observability & Operations
- Infrastructure Observability
- Performance Monitoring
- 24/7 Platform Operations
Multi-Generation GPU Infrastructure - Fully Managed
GPU One delivers production-ready environments across leading NVIDIA GPU platforms, supporting organizations that require the latest advancements in high-performance AI infrastructure:
- NVIDIA H200
- NVIDIA B200
- NVIDIA B300
- NVIDIA GB300
Each generation operates within the same validated platform architecture, networking fabric, security framework, and operational model.
Consistent performance. Predictable operations. Scalable capacity.
When HPE, STN, NVIDIA, and AI pioneers like Skild come together, the result is humanoids and robots doing real work — in healthcare, construction, security, and beyond.
Whether you're building autonomous agents, embodied AI, or next-gen robotic intelligence, STN offers a platform proven in real-world production
You're not deploying into a generic cluster.
You're deploying into the stack that runs the world's most demanding AI workloads.
HPE engineered the platform — the hardware, the direct liquid cooling architecture, the deployment framework, and lifecycle management. They built 7 of the world's top 10 fastest supercomputers1 and hold 300+ direct liquid cooling patents.2
NVIDIA validated the stack. Mission Control, Dynamo, AI Enterprise, TensorRT-LLM — purpose-built for this system, not retrofitted to it.
vs. H1003
for reasoning workloads3
vs. H100 infrastructure3
Think of it as a capacity reservation, not a cloud invoice. The cost structures are not the same.
Dynamic pricing works against sustained AI programs. Every demand spike hits your budget. Every spot market tightening creates compute rationing.
With STN, your cost structure is fixed for the life of the program. No pricing volatility. No surprise invoices. No infrastructure overhead pulling your team away from the work that matters.
Secure GB300 Capacity
Before It's Gone.
Built on HPE GB300 platform. Operated by STN GPU One.
AI infrastructure isn't limited by GPUs.
It's limited by power and scale.
Not on-demand. Not shared.
Reserved, production-grade AI infrastructure.
One partner.
Every layer. Let's talk.
STN works with qualified organizations in healthcare AI, financial services, and enterprise SaaS. Capacity is constrained. If your program timeline fits the reservation window, this is the right conversation to have now.